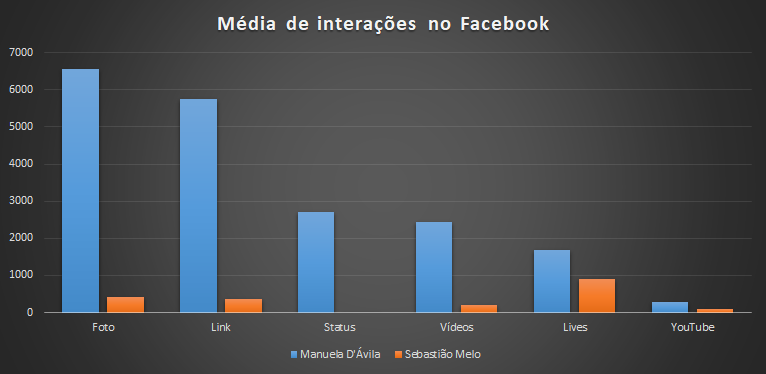
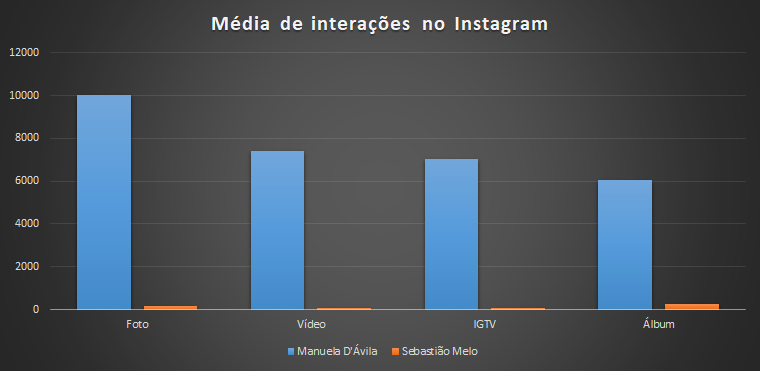
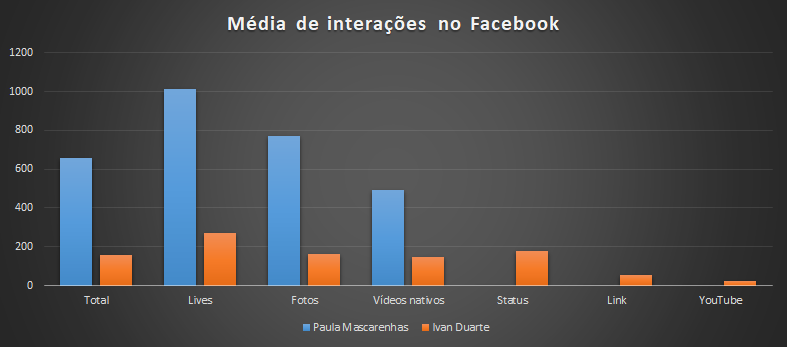
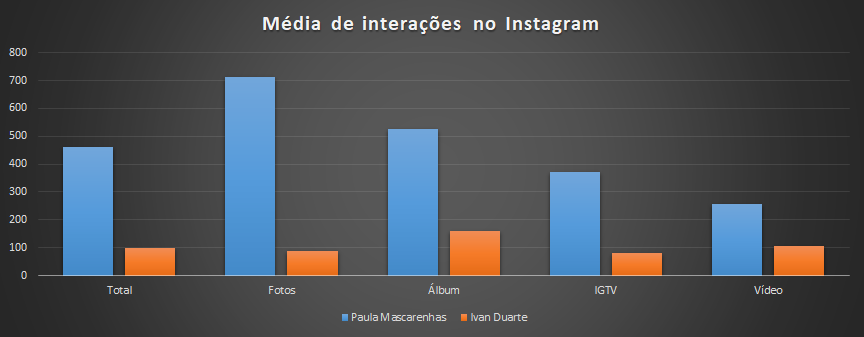
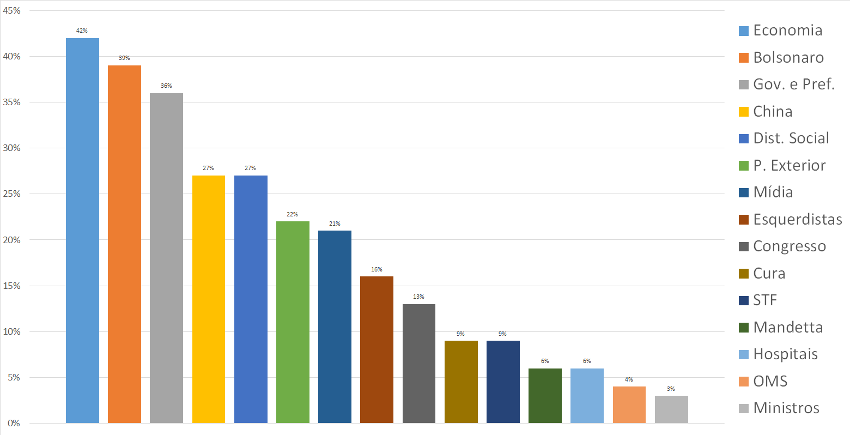
Principais pontos
- Analisamos o compartilhamento de links da imprensa em grupos públicos no Facebook em três eventos relacionados a Covid-19. Particularmente, olhamos para manchetes que poderiam reforçar narrativas de desinformação.
- Descobrimos que os grupos que compartilham as manchetes “problemáticas” não são os mesmos grupos que compartilham outros links da imprensa. Isto é, temos dois ecossistemas de informação distintos.
- Identificamos também que estes links da imprensa com manchetes “problemáticas” são compartilhados em sua maioria em publicações no Facebook acompanhadas de mensagens desinformativas.
Overview
O nosso artigo “How the Mainstream Media Help to Spread Disinformation about Covid-19” foi publicado na última edição do M/C Journal. No artigo, analisamos publicações em grupos públicos no Facebook que incluíam 20 links da imprensa sobre Covid-19. Estes links foram selecionados a partir de uma análise de conteúdo para identificar manchetes que poderiam contribuir para narrativas de desinformação. Dez links possuíam manchetes “problemáticas” e os outros dez foram utilizados como um grupo controle, contendo manchetes sobre as mesmas temáticas, mas sem informações que poderiam reforçar a desinformação. Descobrimos que a maioria dos links que poderiam contribuir para narrativas desinformativas eram compartilhados em grupos que não compartilham os links do grupo controle. Foi o que chamamos de bolha da desinformação, já que também olhamos para as publicações nos grupos públicos com estes links e identificamos que a grande maioria (86,2%) eram acompanhadas de mensagens que reproduziam desinformação – como afirmar que vacinas são perigosas e que medidas de distanciamento social são desnecessárias.
A nossa pesquisa mostra como jornalistas devem estar atentos na produção de manchetes quando publicam notícias. Afinal, manchetes mal construídas, como as que analisamos, acabam sendo utilizadas para legitimar discursos desinformativos nas mídias sociais. Assim, a imprensa pode acabar contribuindo para o espalhamento de desinformação sobre Covid-19.
Método
O primeiro passo para a construção do nosso corpus de análise foi selecionar três eventos relacionados à pandemia de Covid-19 no Brasil. O primeiro evento selecionado foi a repercussão de pronunciamento de Jair Bolsonaro em 24 de março de 2020, quando minimizou a pandemia, criticou as medidas de distanciamento social e afirmou que era necessário salvar a economia. O segundo evento foi quando especialista da OMS falou que a transmissão da doença através de pacientes assintomáticos parecia ser rara. O terceiro evento foi quando a Anvisa interrompeu os testes da vacina Coronavac.
A partir de uma análise exploratória no Facebook, utilizando o CrowdTangle, selecionamos os links da imprensa mais compartilhados sobre cada um dos eventos. Utilizamos a análise de conteúdo (com dois analistas) para identificar manchetes que poderiam reforçar narrativas desinformativas. Por exemplo: (1) “Desemprego é crise muito pior do que coronavírus”, diz Bolsonaro; (2) Pacientes assintomáticos não impulsionam coronavírus, diz OMS. Consideramos problemáticas apenas as manchetes marcadas pelos dois analistas. Destas, selecionamos as dez de maior compartilhamento nos grupos públicos do Facebook para analisar. Para criar um “grupo controle”, que nos ajudaria a identificar onde geralmente circulam as notícias da imprensa, selecionamos também as dez manchetes com maior número de publicações em grupos públicos do Facebook que não foram marcadas como problemáticas por nenhum dos analistas.
A partir destas 20 manchetes, realizamos nova busca com o CrowdTangle. Utilizamos a plataforma para coletar publicações de grupos públicos do Facebook que incluíam o link para alguma destas notícias. No total, coletamos 2762 posts. Utilizamos a análise de redes sociais para mapear os grupos que compartilhavam estes links, identificando “comunidades” que compartilham links semelhantes (métrica de modularidade). Utilizamos também a análise de conceitos conectados para explorar os nomes dos grupos de cada comunidade. Por fim, utilizamos novamente a análise de conteúdo (dois analistas) para analisar as mensagens de posts que compartilhavam as manchetes que reforçavam a desinformação sobre Covid-19.
Resultados
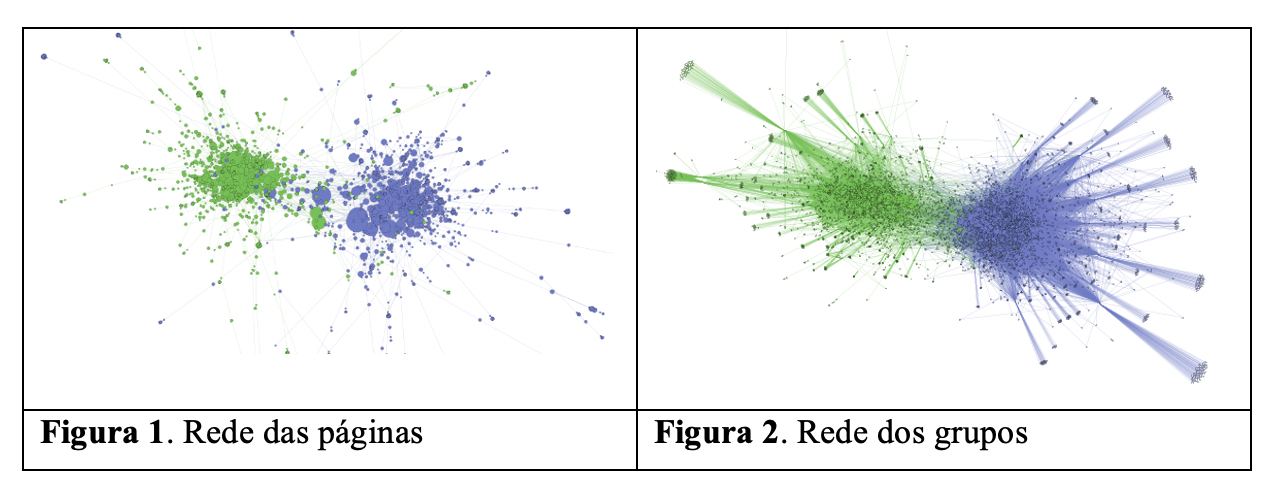
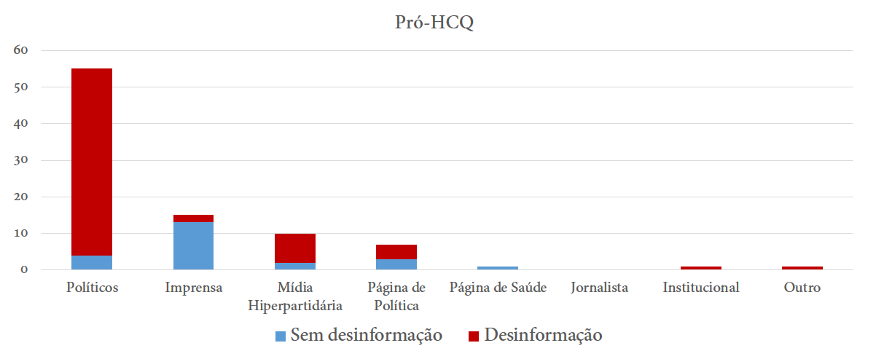
A nossa análise mostra que as manchetes que poderiam reforçar a desinformação são publicadas, em sua maioria, em grupos que não publicam os links do nosso “grupo controle”. No total, apenas 10,7% dos grupos possuíam posts com os links de manchetes problemáticas e posts com links do grupo controle. Entre os outros grupos, 43,8% compartilhou apenas links com manchetes que reforçavam a desinformação e os outros 45,5% compartilharam os outros links da imprensa. Isto pode ser visto na imagem 1, em que links problemáticos estão em vermelho e links do grupo controle estão em azul; e na imagem 2, em que são identificadas duas comunidades a partir da métrica de modularidade (os sete links do grupo roxo foram identificados como problemáticos).
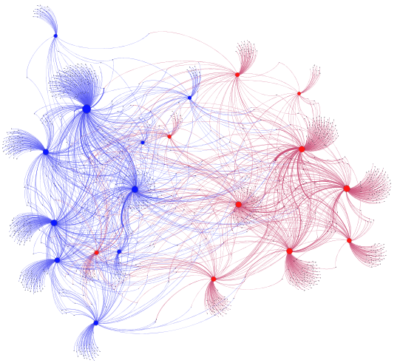
Figura 1. Grafo de rede
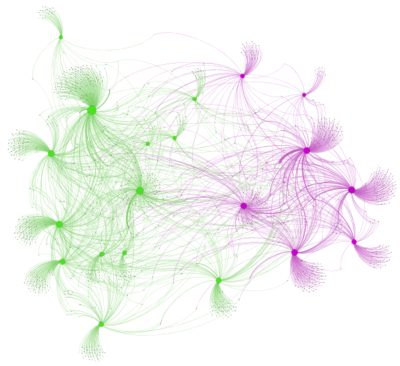
Figura 2. Grafo de rede com modularidade
Para explorar que tipos de grupos faziam parte de cada comunidade, selecionamos os nomes dos grupos e criamos uma rede de conceitos a partir do método chamado análise de conceitos conectados. Este método nos permite identificar os termos mais presentes nos nomes dos grupos e suas conexões (quando aparecem juntos, são parte de um mesmo nome de grupo). Descobrimos que a comunidade roxa (Figura 3), onde circularam as manchetes que reforçavam desinformação, possui alinhamento político próximo de Bolsonaro e outras temáticas da extrema-direita. Entre os grupos mais ativos estão: “Aliança pelo Brasil”, “Bolsonaro 2022”, “Nação Bolsonaro 2022” e “Sou de direita com orgulho”. Já na comunidade verde (Figura 4), Bolsonaro também aparece com centralidade, porém está principalmente associado a conceitos contrários ao seu nome (contra, fora, anti). Também aparecem grupos de esquerda e de localidades (Rio de Janeiro, São Paulo, Rio Grande do Sul, Minas Gerais, entre outros). Estão entre os grupos mais ativos: “Somos 70%”, “União da Esquerda”, “Lula presidente”, “Anti-Bolsonaro”. Portanto, descobrimos que, na média, as duas comunidades representam diferentes discursos políticos.

Figura 3. Rede de conceitos do grupo roxo

Figura 4. Rede de conceitos do grupo verde
Por fim, olhamos para as publicações que compartilhavam links de manchetes problemáticas. Após a análise de conteúdo, descobrimos que 81,8% das publicações com estes links também incluíam mensagens com desinformação no post. Este número é maior na comunidade roxa, que chamamos de “bolha de desinformação”, já que 82,6% dos posts incluíam mensagens com desinformação junto dos links da imprensa. Alguns exemplos de mensagens são: “DESEMPREGO, A CÂMARA DOS DEPUTADOS, O SENADO E O STF MATAM MAIS DO QUE COVID19”; “QUARENTENA FAKE #FicaEmCasa, a mentira do século”; “E o Dória quer te forçar a tomar esta merda [vacina Coronavac]”.
Relevância
A imprensa tem um papel importante na divulgação de informações sobre a pandemia. Porém, manchetes como as que analisamos podem contribuir para a legitimação e o espalhamento de desinformação. Manchetes que apenas reproduzem declarações (desinformativas) de políticos, que se utilizam de clickbaits, ou que incluem informações fora de contexto podem contribuir para o que a Organização Mundial da Saúde chamou de Infodemia. Cabe aos jornalistas e aos veículos de imprensa ter um cuidado especial na produção de manchetes, já que este é o conteúdo mais visível no compartilhamento de notícias em mídias sociais.
Autores e financiamento
Os autores deste artigo são Felipe Bonow Soares (MIDIARS) e Raquel Recuero (UFPEL/UFRGS). O estudo contou com o apoio do CNPq e da FAPERGS. Os dados foram coletados através do CrowdTangle, a quem também agradecemos pelo acesso.